
Introduction
Databricks is an essential platform for many organizations today, offering robust tools for data engineering and data science. However, despite its widespread use, almost every team or client I’ve worked with has developed their own custom processes for writing and deploying code on Databricks. This often leads to inefficiencies, increased costs, and inconsistency.
In this article, I will outline three common methods for testing your local code in Databricks. The goal is to raise awareness, bring clarity, and promote consistency across teams and projects.
Scope: Code Testing in Databricks
Testing is a critical step in the development process. Here’s a typical workflow:
- Write Code: The developer writes the code.
- Test Code: The developer tests the code (focus of this article).
- Push Code: The developer pushes the code (commit/PR/version release).
- Deploy Code: The code may then be deployed to Databricks.
This article (Databricks #1) focuses on testing your code before committing it (green part).
3 Ways to Test Your Code in Databricks
1. Databricks Notebooks
Approach: Write your code directly in Databricks notebooks. You can either maintain them locally using an IDE or use the Databricks interface as your IDE and commit code from there.
Example Scripts:
constants.py
# Databricks notebook source
MY_CONSTANT = "EUROPE"mock_data.py
# Databricks notebook source
MY_DATA = [
(1, "NL"),
(2, "BE"),
]
MY_SCHEMA="""
id integer,
country_cd string
"""main.py
# Databricks notebook source
# MAGIC %run ./constants
# COMMAND ----------
# MAGIC %run ./mock_data
# COMMAND ----------
import pyspark.sql.functions as F
# COMMAND ----------
def run_app(spark_session):
print("running!")
df = spark_session.createDataFrame(
data=MY_DATA,
schema=MY_SCHEMA
)
df = df.withColumn("region", F.lit(MY_CONSTANT))
df.show()
print("succeeded")
return df
# COMMAND ----------
run_app(spark)
# COMMAND ----------Challenges:
- Databricks Restrictions: Each script must start with
# Databricks notebook source. - Complexity: It’s difficult to maintain a typical application code structure in notebooks. Imports, for example, must be done with
# MAGIC %run ./constants, which is not ideal for modular code development.
Testing Options:
- Write Code Locally, Then Copy-Paste into Databricks: This method is error-prone and inefficient (not recommended).
- Write Code Locally, Then Sync Using Databricks CLI: This approach is cumbersome and can lead to version control issues (not recommended).
databricks workspace import \
--format AUTO \
--file /Users/filip/app_1_dbx_notebook/main.py \
/Workspace/Users/filip@cloudnativeconsulting.nl/main.py
3. Write and Test Code Directly in Databricks: Use the Databricks interface for both coding and testing, and commit changes directly (though the version control interface is limited).
Summary:
- Benefits: Simple and easy to get started.
- Drawbacks: Difficult to build complex applications and collaborate with other developers.
- Recommended For: Simple jobs and teams with limited data engineering experience.
2. Local Code with Unit Tests
Approach: Write your code locally and use unit tests with mocked data to test your pipeline each time you make changes.
Setup Requirements:
This approach requires significant upfront investment to create a testing environment that mimics the cloud setup, including:
- Mocked Data Storage: Simulate a cloud storage locally (e.g.,
/tmp/deltalake/). - Spark Session: Set up a local Spark session with Hive metastore.
- Test Suite: Develop a comprehensive test suite.
Example Testing Files:
/tests/mock_data/db_1.py
# mocked data: db_1.table_1
table_1 = {
"database": "db_1",
"table_name": "table_1",
"schema": """
id integer,
country_cd string
""",
"data": [
(1, "NL"),
(2, "BE"),
]
}/tests/conftest.py
import pytest
from pyspark.sql import SparkSession
from config import Environments
from context import SparkContextCreator
from setup import drop_all_tables, setup_hive
@pytest.fixture(scope="session", autouse=False)
def spark_session() -> SparkSession:
spark = SparkContextCreator(
app_name="test_spark_session",
environment=Environments.LOCAL,
).get_session()
drop_all_tables()
setup_hive(spark)
yield spark
spark.sparkContext._gateway.shutdown_callback_server()
spark.stop()
/tests/unit/test_app_2.py
import pytest
from databricks_dev_workflow.app_2_local_spark.app.main import run_app
@pytest.mark.unit
def test_run_app(spark_session):
run_app(spark_session)Execution:
Command: Run your tests using:
pytest -vsProcess: This command initiates a local testing environment, drops old Hive tables, and creates new ones. You’ll see output like:
>>> dropping table(s) in /tmp/deltalake
>>> Succesfully dropped tables in /tmp/deltalake
>>> Setting up Hive Metastore
>>> ...
>>> Created Hive table: db_1.table_1
>>> running!
>>> +---+----------+------+
>>> | id|country_cd|region|
>>> +---+----------+------+
>>> | 1| NL|EUROPE|
>>> | 2| BE|EUROPE|
>>> +---+----------+------+
>>> succeeded
>>> PASSEDSummary:
- Benefits: Fast local testing, no need for a remote environment, and the ability to add detailed tests for different code components.
- Drawbacks: Complex setup, difficult to maintain, especially with frequently changing mock data, and specialized tests may require frequent updates.
- Recommended For: Teams with strong engineering expertise who need custom unit tests and are willing to invest in maintaining mock data.
3. Databricks CLI (Databricks Connect)
Approach: Write your code locally, use Databricks Connect to sync your code seamlessly between your local environment and Databricks workspace, and run selected scripts in the cloud.
Setup:
- Both VSCode and PyCharm offer plugins for Databricks Connect.
- After installing the plugin, authenticate and configure it, then select the syncing space.
Example:
- Plugin installation:
- After configuring we are ready to go:
- Syncing in action:
>>> [VSCODE] databricks cli path: /Users/filip/.vscode/extensions/databricks.databricks-1.3.1-darwin-arm64/bin/databricks
>>> [VSCODE] sync command args: sync,.,/Users/filip.../.ide/shared_code,--watch,--output,json,--log-level,debug,--log-file,/Users/filip/Library/Application
--------------------------------------------------------
>>> Starting synchronization (49 files)
>>> Deleted databricks_dev_workflow/local_testing/app_2_local_spark/tests/conftest.py
>>> ...
>>> ...
>>> ...
>>> Uploaded databricks_dev_workflow/app_3_dbx_connect/mock_data.py
>>> Uploaded readme.md
>>> Completed synchronization- After running the sync command, the
databricks_dev_workflowfolder is synced, allowing you to run your code on Databricks.
- After running the code:
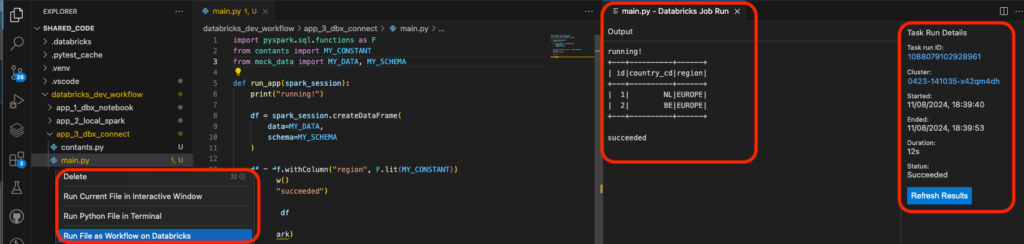


Summary:
- Benefits: Easy setup, allows modular code structure with reusable components, and the ability to test code with actual production data.
- Drawbacks: Minimal, depending on the complexity of your environment and data.
- Recommended For: Teams with a need for robust testing of complex applications that benefit from using real data in a cloud environment.
Common testing mistakes
1. Testing Only After Deployment
Avoid the temptation to make “small” changes and deploy them without proper testing, thinking “what could go wrong?” This can lead to errors discovered only after deployment, wasting time and resources.
2. Relying Solely on CI/CD for Testing
While CI/CD pipelines are valuable, relying on them for all testing can slow down development, especially when dealing with flaky or unavailable tools. Testing locally before pushing can save time and reduce frustration.
3. Using Only Mock Data in Dev Environment
Mock data is useful, but it’s crucial to test your code against real production data when possible. This ensures your code performs as expected in the actual environment, despite the potential costs.
4. Not Thoroughly Comparing Changes
Simply thinking something “kind of makes sense” isn’t enough. Carefully compare old and new data, and ensure every difference is understood. While tedious, this effort leads to better sleep, satisfied stakeholders, and a higher-quality product.
Summary
I highly recommend Databricks Connect as a powerful yet user-friendly tool for testing Databricks code. You can also develop directly within the Databricks environment using the Databricks IDE, which provides a seamless experience. For those who prefer more flexibility, setting up a local environment to run unit tests with mocked data is another effective, though less common, approach. Whichever method you choose, these tools empower you to create, test, and refine your Databricks code with confidence, setting you up for success.
Happy coding!
Filip